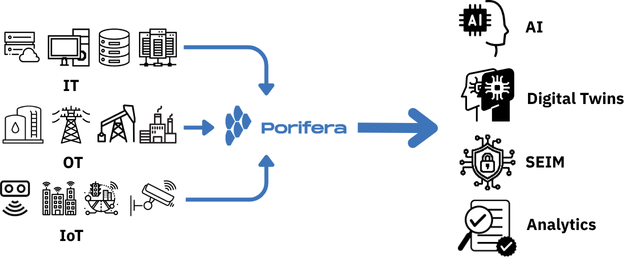
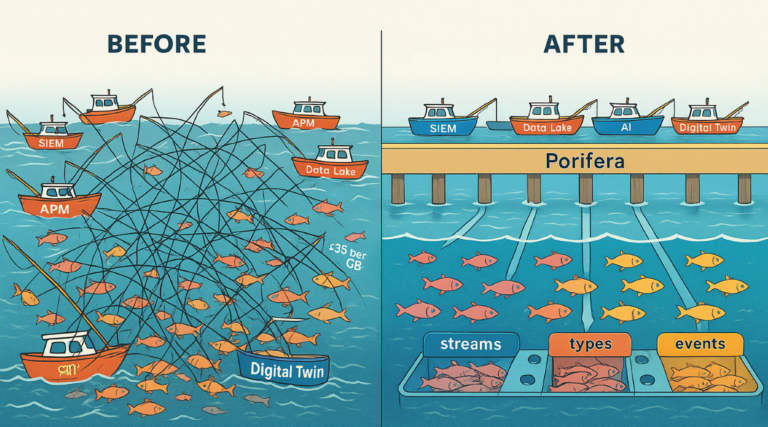
Porifera is an independent data-control layer that collects, shapes, and delivers clean, real-time IT, OT, and IoT data to your systems and platforms—on-premises, in the cloud, or hybrid—without vendor lock-in or per-GB fees.
Porifera is an upstream data-control layer that standardizes how data enters, changes, and moves across IT, OT, and IoT. It decouples sources from tools so you can add or swap destinations without touching collectors, and replace scripts with policies that decide what’s kept, transformed, or dropped.
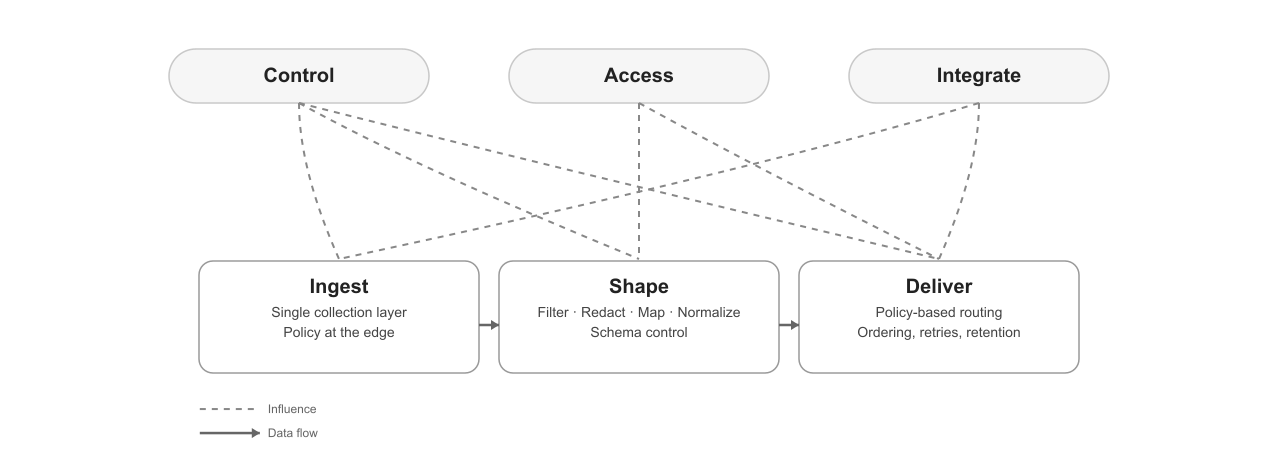
Core Capabilities
Ingest
A single upstream ingestion layer across environments
Continuous capture with local buffering in case of connectivity lose
Central source definitions rolled out safely across sites
Shape
Filtering, redaction, field mapping, normalization, enrichment
Keep-only and deny rules to remove noise before costs accrue
Schema guarantees so every consumer gets predictable JSON
Deliver
Policy-based routing with delivery guarantees
One-to-many destinations including SIEM, analytics, digital twins, and AI
Add or change destinations without redeploying collectors
A single upstream ingestion layer across environments
Continuous capture with local buffering in case of connectivity lose
Central source definitions rolled out safely across sites
Filtering, redaction, field mapping, normalization, enrichment
Keep-only and deny rules to remove noise before costs accrue
Schema guarantees so every consumer gets predictable JSON
Policy-based routing with delivery guarantees
One-to-many destinations including SIEM, analytics, digital twins, and AI
Add or change destinations without redeploying collectors
Porifera - Promise to Capability Map
How It Works
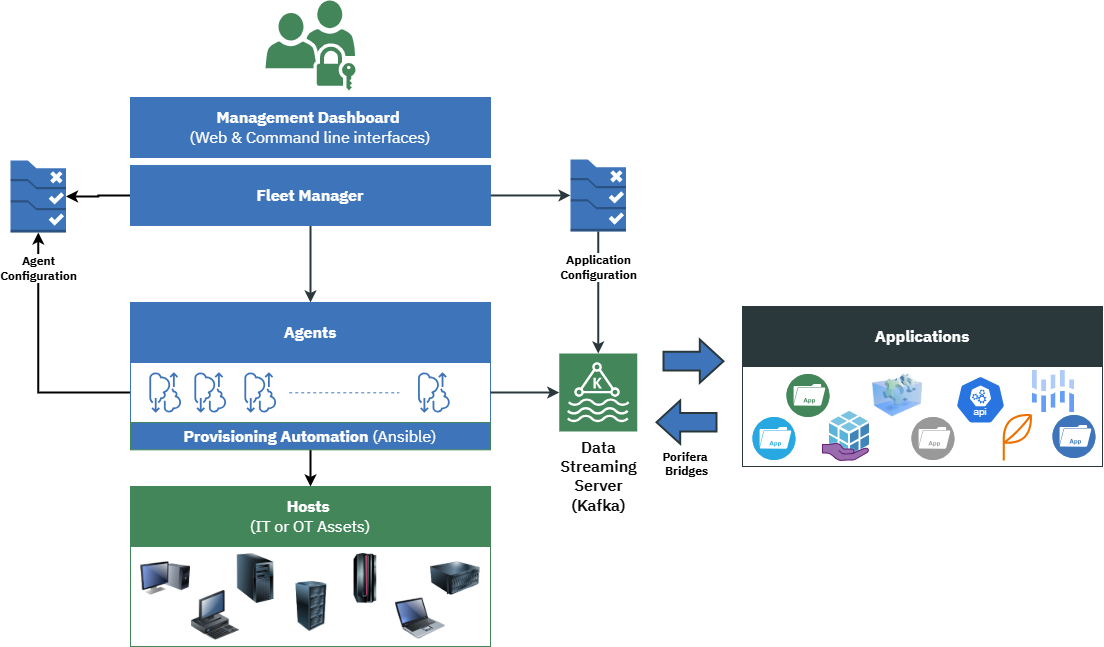
Porifera operates through four core components:
Agent: A lightweight edge collector for IT, OT, and IoT data. It performs local shaping, including filtering, enriching, throttling, and masking, before streaming normalized events. Fleet Manager: A central control service that manages configurations for agents and bridges and organizes the infrastructure into data clusters. Bridge: A modular connector that sends normalized Kafka streams to downstream systems such as BI, SIEM, AI, digital twins, and data lakes in vendor-neutral formats. Dashboard: A web interface that shows end-to-end data flows with live metrics such as throughput, drops, latency, and errors, and includes a CLI for advanced users.
Flow: Define policy in fleet manager → agents apply it at the edge → data moves over streaming → destinations consume the same standardized stream in parallel.
Get Operational In Days, Not Months
Deploy, Secure, and Operate
Deployment
Security
Operations and Observability
Deployment
Containerized on your infrastructure, on premises or cloud
Agents belong to clusters and inherit their configuration
One token per cluster for agent registration and signed configuration pulls
Versioned configuration with staged rollout and rollback
Security
OAuth 2.0 and OIDC with role based access and audit trails
Cluster scoped tokens for agent enrollment and configuration
Encryption in transit with optional encryption at rest
Policy based redaction and field filtering at the edge
Operations and Observability
Metrics for heartbeats, throughput, lag, error rates, and queue depth
Dashboards to visualize end to end delivery
Admin UI and CLI for diffs, dry run, rollout, and rollback
Audit logs for configuration and token changes
Supported Data Sources and Destinations
Sources
Examples of Data Sources Supported
IT: Windows Event Log, Syslog, HTTP/NGINX/Apache logs, App logs, DB query taps, Message queues.
OT: OPC UA (passive wire parsing), Modbus/TCP, BACnet/IP, DNP3, and IEC-62056.